In this post, you’ll explore the mathematical foundations of sequence-to-sequence (seq2seq) models for machine translation. We’ll focus on the RNN Encoder–Decoder architecture, which consists of two main components: an encoder RNN and a decoder RNN. As an example, we’ll see how this model can be trained to translate English phrases into French 🇬🇧➡️🇫🇷.
Definition¶
¶
Sequence-to-Sequence (Seq2Seq) is a deep learning framework designed to convert an input sequence (e.g., a sentence in French) into an output sequence (e.g., its English translation). It consists of two main components:
– Processes the input sequence and compresses it into a , a fixed-length representation capturing the input’s semantics.
– Generates the output sequence , conditioned on the context vector from the encoder.
Key Features
Handles variable-length input and output sequences (e.g., translating sentences of different lengths).
Supports various architectures: RNNs, LSTMs, GRUs, and more recently, Transformers (state-of-the-art).
Trained end-to-end using teacher forcing i.e., during training, the decoder is fed the true previous token rather than its own prediction.
Preliminaries: Recurrent Neural Networks¶
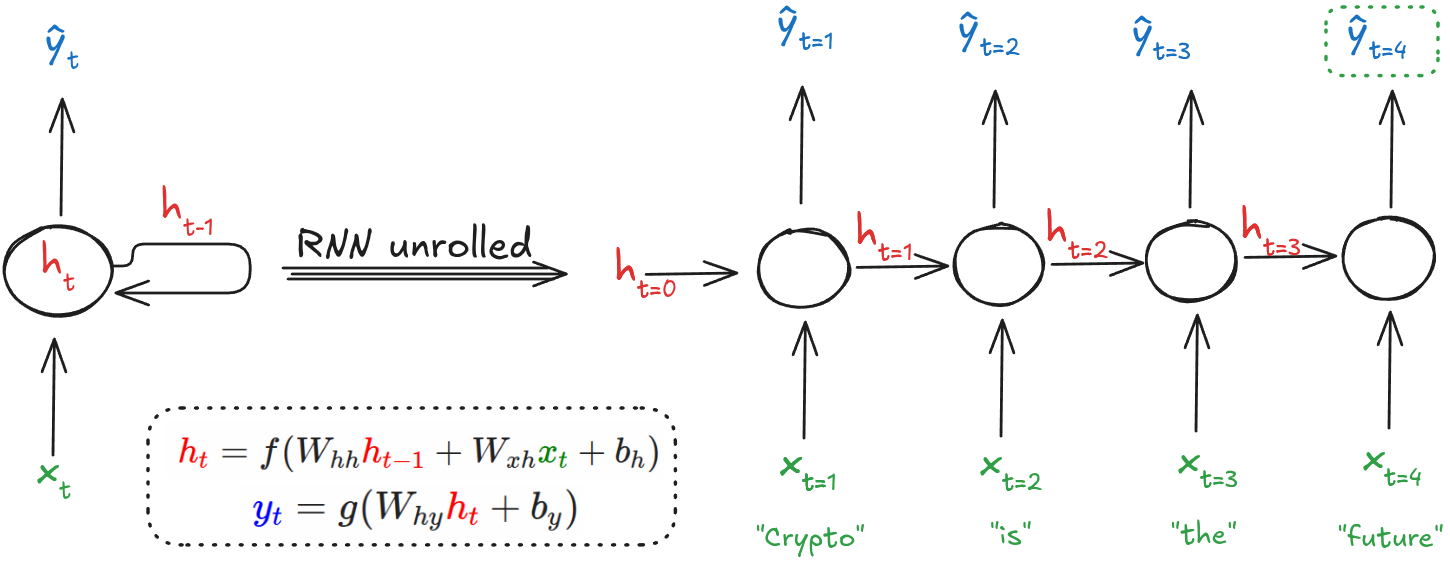 Figure 1: RNN Architecture (Image by the author).
Figure 1: RNN Architecture (Image by the author).
The input ¶
In a Recurrent Neural Network (RNN), the input at time step , denoted as , represents the data fed into the network at that point in the sequence. It is typically a vector (e.g., a word embedding) in , where is the embedding dimension.
As an example, lte’s consider the 4-word sentence: . This sequence has length . The corresponding inputs are:
Hidden State ¶
The hidden state serves as the network’s internal memory, encoding contextual information from the sequence up to time . It is updated as shown above, and plays a key role in maintaining temporal dependencies. At each time step, the hidden state is updated based on the current input and the previous hidden state :
Here and are weight matrices, is a bias vector, and is a nonlinear activation function such as or ReLU.
Initial Hidden State ¶
The initial hidden state represents the starting memory of the RNN before any input is processed. It is typically initialized in one of the following ways:
As a zero vector:
where is the dimensionality of the hidden state.With small random values (e.g., sampled from a normal distribution):
As a learned parameter:
can also be treated as a trainable vector that is learned during training, allowing the model to adapt its initial memory based on the data.
The choice depends on the specific task, model design, and desired behavior at the start of the sequence.
Output ¶
The output at time step is computed from the hidden state:
where is the output weight matrix, is a bias vector and is an activation function such as softmax or sigmoid, depending on the task.
RNN Encoder–Decoder¶
The RNN Encoder–Decoder architecture, introduced by Cho et al. (2014) and Sutskever et al. (2014), operates by encoding an input sentence into a fixed-length vector and then decoding it to generate an output sequence.
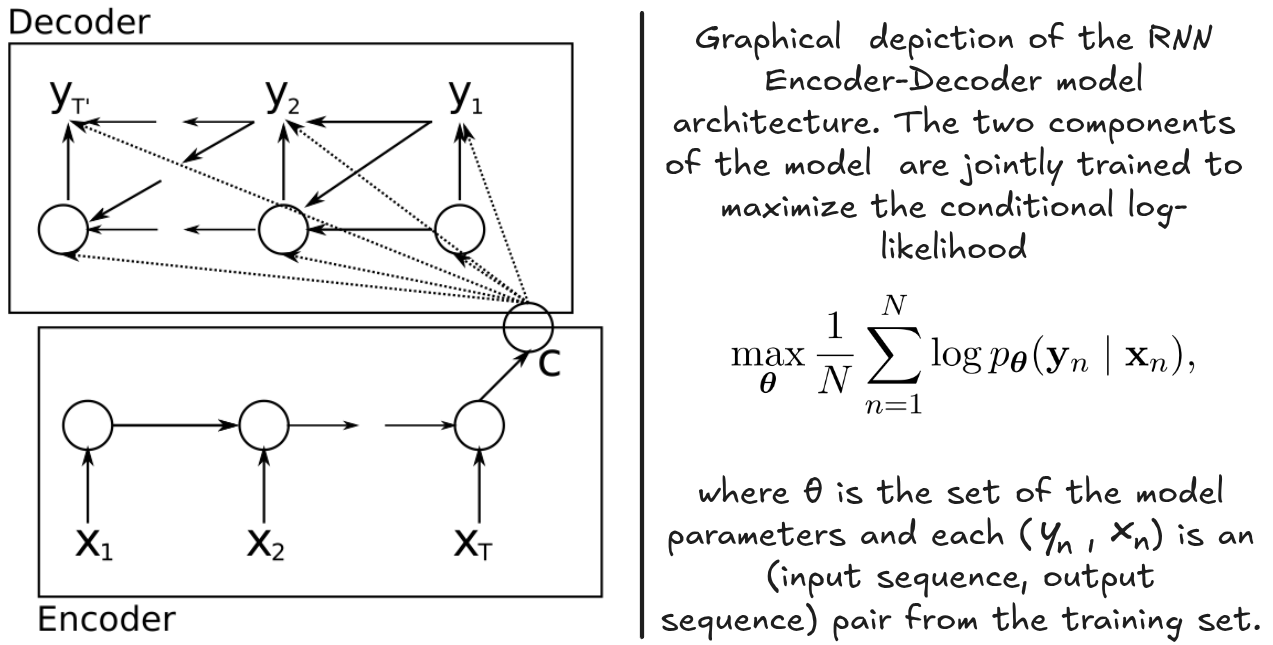
Figure 2: Encode-Decoder architecture (Image and comment from Cho et al. (2014)).
In this framework, the encoder processes the input sequence and transforms it into a context vector . Typically, a recurrent neural network (RNN) is employed for this transformation as follows:
and
Here, represents the hidden state at time step , and the context vector is derived from the sequence of hidden states. The functions and are nonlinear operations; for example, Sutskever et al. (2014) used an LSTM for and set .
The decoder is trained to generate each word based on the context vector and the previously generated words . It models the probability distribution over the output sequence by factorizing it into a product of conditional probabilities:
where .
When using an RNN, each conditional probability is computed as , where is a nonlinear function (possibly multi-layered) that outputs the probability of , and denotes the decoder’s hidden state at time .
Time to Dive into the Implementation 💻¶
- Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 10.3115/v1/d14-1179
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. arXiv. 10.48550/ARXIV.1409.3215